마지막 업데이트 2024. 9. 30. UID, GID 관련 내용 추가.
인공지능을 연구함에 있어 그래픽카드는 비싼 물건이면서, 반드시 필요한 물건이다.
중요한 만큼 관리도 열심히 해야하는데, 그래픽카드가 잘 돌아가고는 있는지, 알고보니 0번만 일하고 나머지가 놀고 있는지 모니터링이 필요할 것이다.
그렇지만, nvidia-smi를 출력하면 순간의 결과는 나오지만 이것이 누적되어서 관찰할 수는 없다.
그래서 모니터링을 하는 도구를 모아서 이쁘게 웹서비스를 통해 시작을 하여보자.
많은 내용을 Prometheus + Grafana + Docker Compose 설치에서 참고하였습니다. 저는 여기에 nvidia-smi-exporter와의 연결을 추가하여 작성하였습니다.
준비하기
우리는 GPU를 모니터링을 하기 위해서 docker라는 도구를 활용할 것이다. 도커를 통해서 필요한 프로그램을 컨테이너에 담아 실행을 하고, 이를 웹 서비스 포트를 통해 공유하고 싶다. (자세한 도커 설명은 여기서 논외로 하자…) 설치방법은 공식 홈페이지 링크를 참조하자. Link
구성
본 블로그 글을 참고하여 작성하였습니다. Prometheus + Grafana + Docker Compose 설치
우리는 GPU를 모니터링 하기 위하여 아래 세 가지 docker를 활용할 예정입니다.
- Nvidia-smi-exporter: GPU 모니터링을 추가 프로그램을 설치하지 않고
nvidia-smi에 나오는 정보를 얻게 되는 컨테이너이다. 이를 통해 우리는 정해진 API 형식으로nvidia-smi정보를 얻을 수 있다. - Prometheus: 모니터링을 하는 도구로써, 시간에 따른 상태를 누적해서 저장하는 프로그램이다. 우리는 1.의 프로그램과 결합하여서 GPU에 대한 정보를 prometheus를 통해 관리할 것이다.
- Grafana: 모니터링하는 정보를 시각적으로 보여주는 도구이다. 이를 통해서 2.에서 얻은 정보를 웹을 통해 시각적으로 보여줄 것이다.
여기서 "$UID:$GID"는 설정 및 도커에서 관리하는 파일의 소유권한을 지정할 user 및 group이다. $ id 를 통해 자신의 UID와 GID를 알 수 있으며, 별도의 관리용 계정을 만든다면 그것의 UID, GID를 사용하면 된다. 이후, ./prometheus 및 ./grafana 디렉토리의 소유권한을 해당 uid, gid를 적용하면 된다.
구조는 여러 도커가 실행되지만, 실제 연산 노드 (GPU로 연산을 수행하는 노드) 에서는 nvidia-exporter와 prometheus만 있으면 됩니다. 그리고 홈페이지를 호스팅할 서버에는 grafana만 있으면 됩니다. 이를 응용한다면, 연산 노드에서는 nvidia-exporter와 prometheus만을 yaml에 넣으면 되고 (grafana로 시작하는 부분을 지우고), 호스팅할 서버에서는 grafana 만을 남기는 방법이 있습니다. 이 경우
version: '3.7' # 파일 규격 버전
services: # 이 항목 밑에 실행하려는 컨테이너 들을 정의
nvidiaexport:
image: utkuozdemir/nvidia_gpu_exporter:1.1.0
container_name: nvidia_exporter
volumes:
- /usr/lib/x86_64-linux-gnu/libnvidia-ml.so:/usr/lib/x86_64-linux-gnu/libnvidia-ml.so
- /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1:/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1
- /usr/bin/nvidia-smi:/usr/bin/nvidia-smi
ports:
- 9835:9835
devices:
- /dev/nvidiactl:/dev/nvidiactl
- /dev/nvidia0:/dev/nvidia0 # 0번 부터 GPU가 할당된다. 모니터링하고 싶은 GPU를 넣으면 된다.
restart: always
networks:
- promnet
prometheus:
image: prom/prometheus
container_name: prometheus
user: "$UID:$GID"
volumes:
- ./prometheus/config:/etc/prometheus
- ./prometheus/volume:/prometheus
ports:
- 9090:9090
command:
- '--config.file=/etc/prometheus/prometheus.yml'
restart: always
networks:
- promnet
grafana:
image: grafana/grafana
container_name: grafana
user: "$UID:$GID"
ports:
- 3000:3000 # 접근 포트 설정 (컨테이너 외부:컨테이너 내부)
volumes:
- ./grafana/volume:/var/lib/grafana
networks:
- promnet
networks:
promnet:
driver: bridge
prometheus 관련 설정을 docker-compose.yml이 있는 디렉토리 아래에 아래와 같이 디렉토리를 생성하자
mkdir prometheus
mkdir prometheus/config
touch prometheus/config/query_log_file.log
이후 ./prometheus/config/prometheus.yml 이라는 파일을 아래와 같이 생성하자
global:
scrape_interval: 15s # scrap target의 기본 interval을 15초로 변경 / default = 1m
scrape_timeout: 15s # scrap request 가 timeout 나는 길이 / default = 10s
evaluation_interval: 2m # rule 을 얼마나 빈번하게 검증하는지 / default = 1m
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor' # 기본적으로 붙여줄 라벨
query_log_file: query_log_file.log # prometheus의 쿼리 로그들을 기록, 없으면 기록안함
# 규칙을 로딩하고 'evaluation_interval' 설정에 따라 정기적으로 평가한다.
rule_files:
- "rule.yml" # 파일 위치는 prometheus.yml 이 있는 곳과 동일 위치
# 매트릭을 수집할 엔드포인드로 여기선 Prometheus 서버 자신을 가리킨다.
scrape_configs:
# 이 설정에서 수집한 타임시리즈에 `job=<job_name>`으로 잡의 이름을 설정한다.
# metrics_path의 기본 경로는 '/metrics'이고 scheme의 기본값은 `http`다
- job_name: 'monitoring-item' # job_name 은 모든 scrap 내에서 고유해야함
scrape_interval: 10s # global에서 default 값을 정의해주었기 떄문에 안써도됨
scrape_timeout: 10s # global에서 default 값을 정의해주었기 떄문에 안써도됨
metrics_path: '/metrics' # 옵션 - prometheus가 metrics를 얻기위해 참조하는 URI를 변경할 수 있음 | default = /metrics
honor_labels: false # 옵션 - 라벨 충동이 있을경우 라벨을 변경할지설정(false일 경우 라벨 안바뀜) | default = false
honor_timestamps: false # 옵션 - honor_labels이 참일 경우, metrics timestamp가 노출됨(true일 경우) | default = false
scheme: 'http' # 옵션 - request를 보낼 scheme 설정 | default = http
params: # 옵션 - request요청 보낼 떄의 param
# 실제 scrap 하는 타겟에 관한 설정
static_configs:
- targets: ['172.17.0.1:9835'] # 프로메테우스가 가져올 설정 정보는 도커 네트워크 상 9835 서버에 있다. 일반적인 도커 네트워크는 172.17.0.1이라는 사설 IP를 가진다.
labels: # 옵션 - scrap 해서 가져올 metrics 들 전부에게 붙여줄 라벨
service : 'monitor-1'
./prometheus/config/rule.yml은 아래와 같이 작성한다.
groups:
- name: example # 파일 내에서 unique 해야함
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
이후 아래 명령어로 세 도커를 실행하도록 하자
docker compose up -d
Grafana
Grafana에 접속을 하는 방법은 웹 페이지에서 <해당 서버 IP>:3000 이다.
기본 ID/PW는 admin admin으로 로그인을 하면 바꾸게 되어 있다.
먼저 우리의 nvidia-exporter에서의 data sources를 설정하자. 우측 상단 로고 아래 햄버거 버튼에서 Connections > Data Source에서 선택할 수 있다.
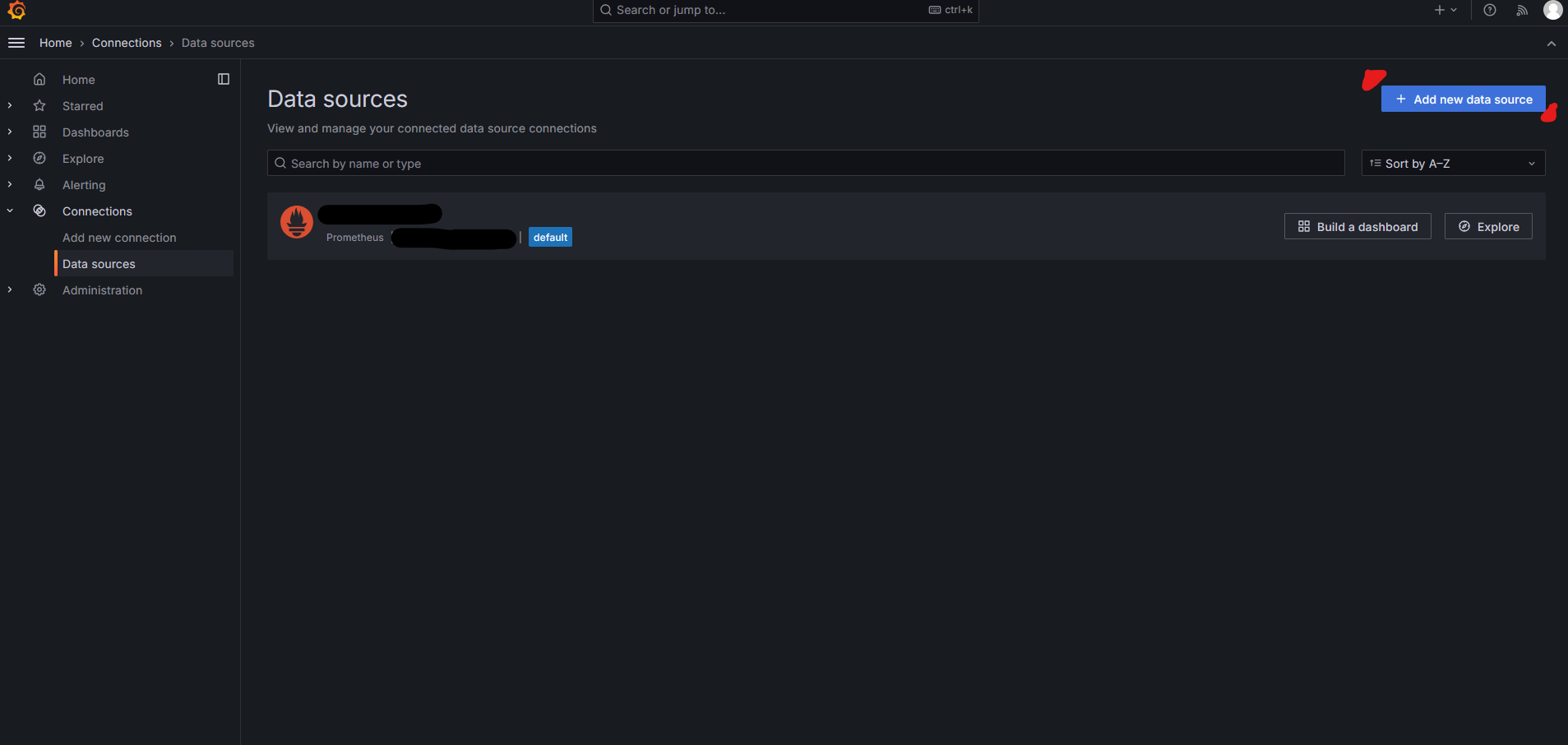
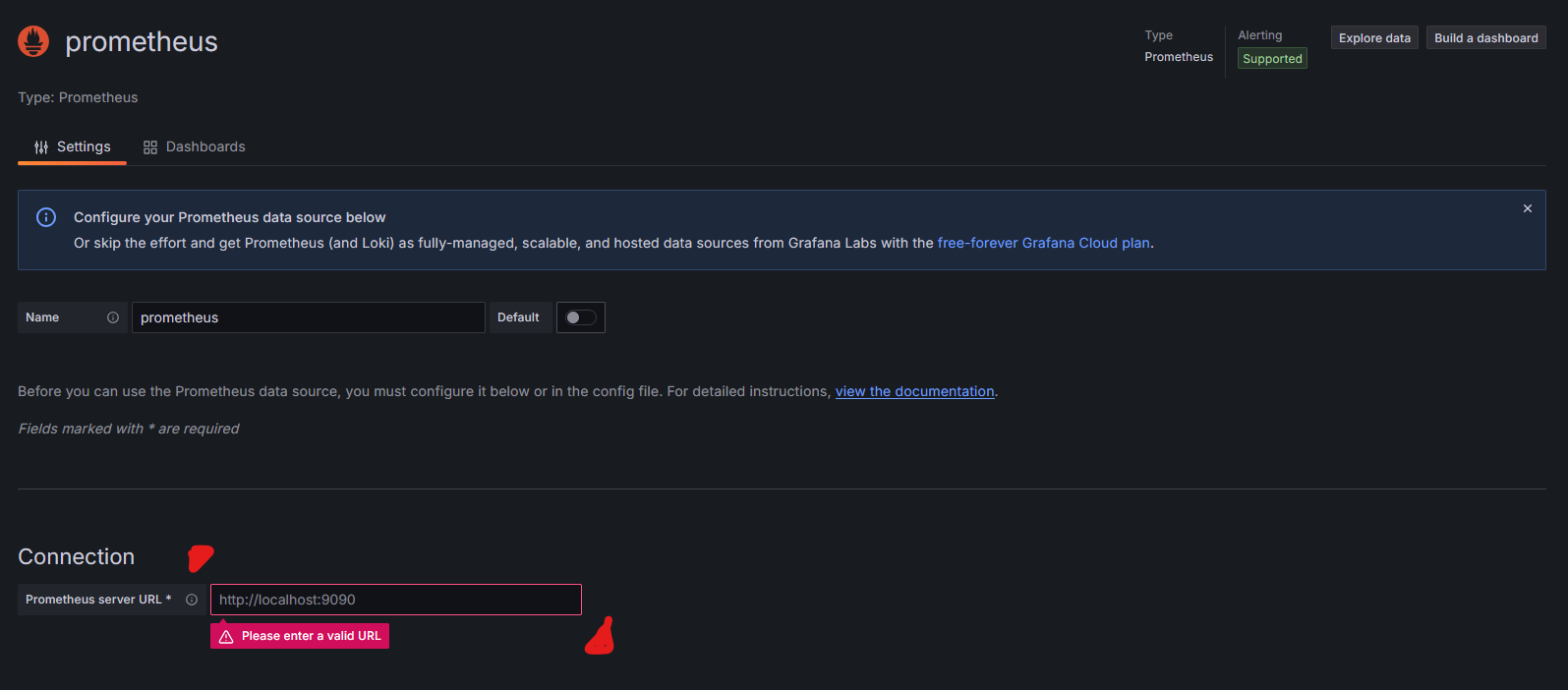
우측 “Add new data source” 버튼을 누르고 Prometheus를 누르자. 이후 Connection에서 서버의 ip와 port를 입력하면 data source에 추가된다. Name의 경우 추후, 여러 서버에서 모니터링할 내용이 있다면 헷갈릴 수 있으니 구분지을 수 있게 작성하도록 하자.
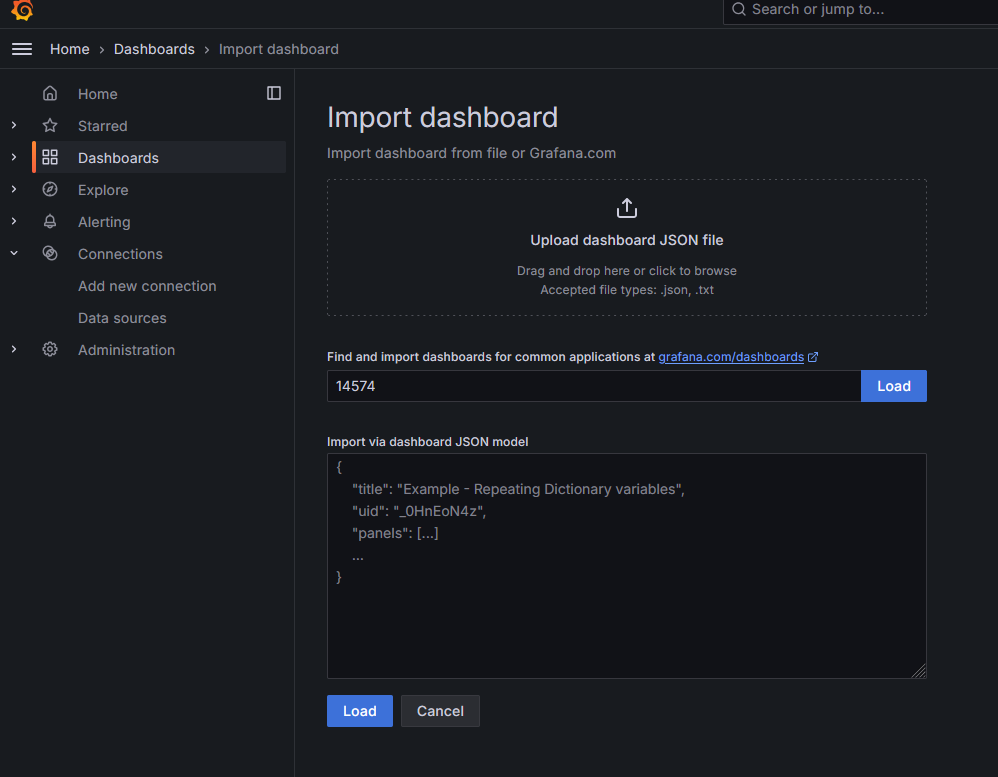
Dashboard는 nvidia_exporter 제작자님께서 친절하게 만들어주셨다. 해당 템플릿을 바로 활용하면 된다. Link New > New dashboard > Import dashboard 에서 “14574” 숫자를 입력하고 옆 Load를 누르면 해당 템플릿을 바로 불러올 수 있다. 이후 옵션에서 Name, prometheus에서 우리가 추가한 data source의 name을 선택하면 완료된다.
Unique identifier의 경우 직접 설정이 가능합니다. 이후 이를 통해 링크가 생성되니, 서버 이름과 연관되어 지으면 편리합니다.
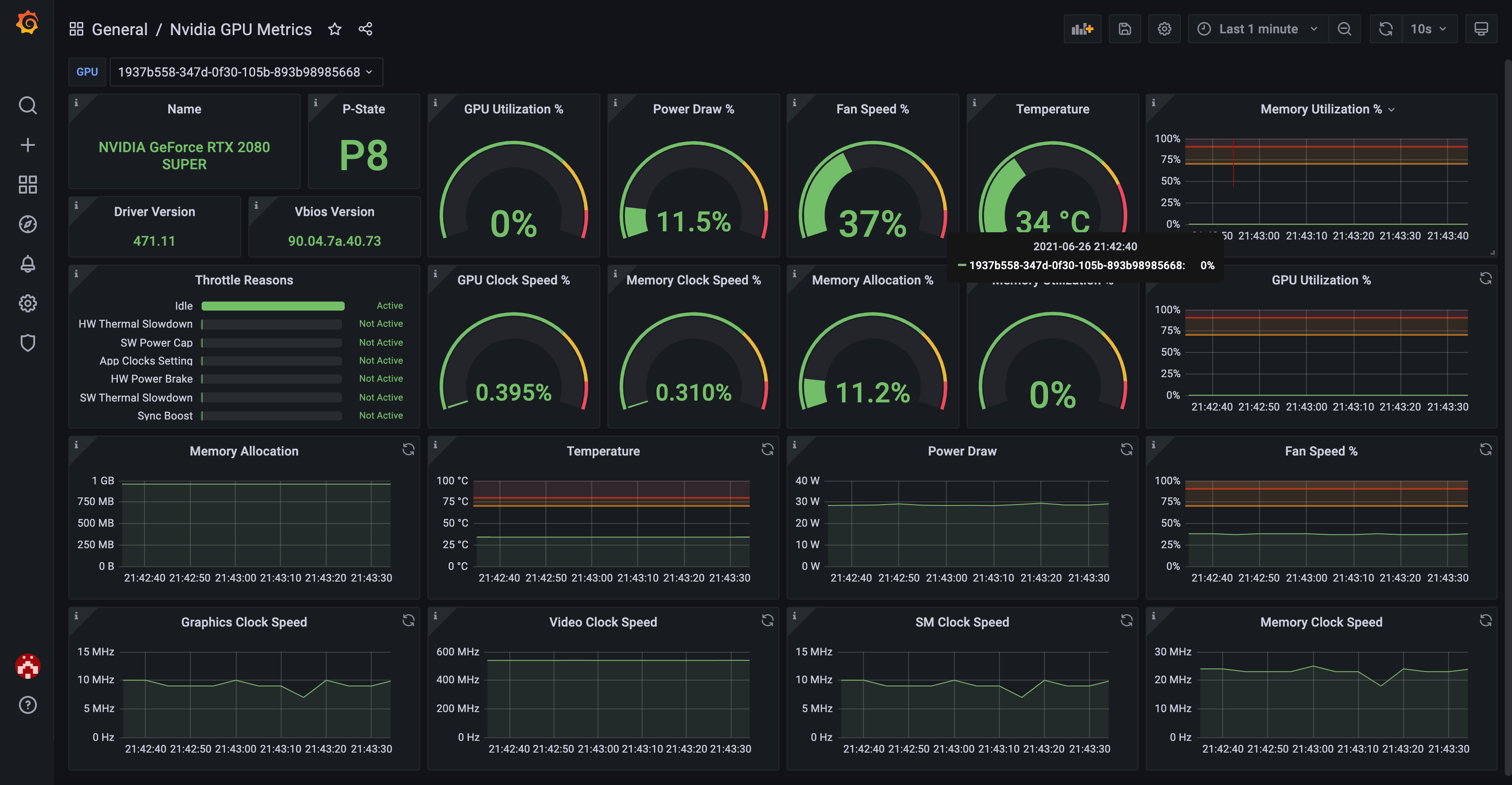
예시 이미지와 같이 여러 GPU를 볼 수 있으면 완성되었다.